
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- GCP
- cdk
- coursera
- docker
- 구글
- cloud
- 클라우드 자격증
- 네트워크
- Associate
- go
- 자격증
- 딥러닝
- 마이크로서비스
- 쿠버네티스
- Dataproc
- aws
- golang
- AWS #빅데이터 #분석 #데이터
- 구글 클라우드
- 구글클라우드서밋
- 코세라
- 클라우드
- DataFlow
- 구글클라우드
- 도커
- 머신러닝
- nnictl
- Kubernest
- 구글클라우드플랫폼
- Today
- Total
JD의 블로그
[Coursera] Google Cloud Associate Engineer Prepare - Week 4 ( 클라우드 솔루션 계획 및 구성 ) 본문
[Coursera] Google Cloud Associate Engineer Prepare - Week 4 ( 클라우드 솔루션 계획 및 구성 )
GDong 2019. 11. 27. 06:39
*Week 2 - ACE 자격증은 무엇이고 어떻게 준비하는가?
*Week 3-1 - 클라우드 솔루션을 위한 가장 기본적인 단계 ( 프로젝트와 계정 )
*Week 3-2 - 클라우드 솔루션을 위한 가장 기본적인 단계( 결제 관리와 CLI )
이제 절반 정도 왔습니다! 시작이 반이라는데 벌써 절반이군요. ACE 자격증 취득도 멀지 않아 보입니다..
Week 4에는 Module 3 내용으로 클라우드 솔루션 계획 및 구성 (Planning and configuring a cloud solution)에 대해서 다뤄보겠습니다.

2.1 가격 계산기를 사용하여 계획하고 추정하기 ( Planning ad estimating using the Pricing Calculator )

새 프로젝트를 설정할 때 가장 먼저 해야할 것은 예산 측정입니다. 여러 변수를 통해 서비스 사용료를 측정할 수 있기 때문에 실제로 서비스를 구성하지 않고도 Pricing Calculator를 통해 예산을 측정해볼 수 있습니다. 그러나, 이러한 예측치는 실제 사용량에 따라 다를 수 있으므로 주의해야 합니다. 예측치는 하루, 한 주, 한 달, 한 분기, 일 년 등의 단위로 예측이 가능합니다. ( 처음 12개월 300$ 크레딧을 받아 GCP를 시작하는 당신! 아무 서비스나 건드렸다가 하루 만에 100$ 크레딧이 날아가버리는 불상사가 생길 수도 있다고! - 경험담 )
Pricing Calculator 사용법
1. 먼저 상단바에서 사용할 제품을 선택합니다.
2. 목표 configuration에 맞춰 하단의 폼을 채워넣습니다.
( 하단의 예시는 Compute Engine을 사용하기 전에 Pricing Calculator를 통해 사용량에 따른 요금을 측정해보고자 한 것입니다. )
3. ADD TO ESTIMATE 버튼을 누릅니다.


2.2 컴퓨트 리소스 계획하고 구성하기 ( Planning and configuring copute resources )

컴퓨트 리소스는 컴퓨팅 작업에 사용하는 가상머신(VM)이나 서버를 말합니다.
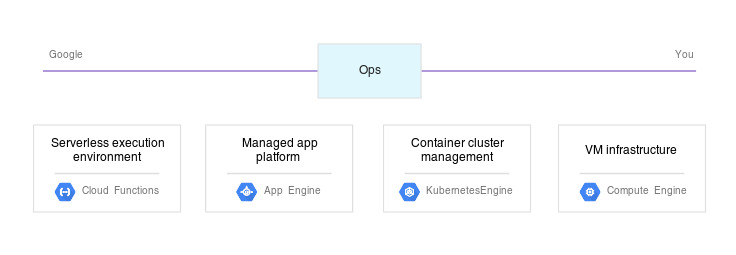
* GCP 내에서 선택할 수 있는 컴퓨팅 리소스가 여러 가지이며, 여러 컴퓨팅 리소스(e.g Compute Engine, Google Kubernetes Engine, App Engine 등)는 각각의 장점과 특징을 가집니다.
* 필요에 따라 선점형 VM과 사용자 머신 타입을 사용할 수 있습니다.
이번 세션에서는 사용에 따라 어떤 컴퓨팅 리소스를 선택해야할지에 대해 집중해보려고 합니다.

[1] App Engine : 관리형 애플리케이션 플랫폼
실제 특별한 런타임이 요구되지 않으며 앱을 관리하기 위해 서버를 설정하고 유지 관리하고 싶지 않은 경우 App Engine이 가장 좋은 선택입니다.
* 코드를 작성하는 데 집중하게 해줍니다.
( 소규모든 대규모든 애플리케이션을 자동 확장 / 축소하는 기능이 있고 서버에 대한 완전 관리형 패치 및 관리 기능을 제공해줘서 개발자는 코드 작성에만 집중할 수 있게 되었다. )
* 개발 속도가 중요한 경우 유용합니다.
* 운영의 오버헤드를 줄이기 좋습니다.
* App Engine은 애플리케이션 트래픽에 따라 자동으로 확장되며, 코드가 실행 중일 때만 리소스를 사용한다.
[2] Google Kubernetes Engine : 유연성 확보를 위한 컨테이너 기술 활용
만약 컨테이너화 된 프로그램 또는 마이크로서비스를 온프레미스 환경에서 실행하거나 1개 이상의 클라우드 환경에서 운영하기 위한다면, Kubernets Engine은 좋은 선택이 될 수 있습니다.
* 특정한 OS에 종속되지 않게 해 줍니다.
* 속도와 작동 능력을 향상시켜줍니다.
* 개발에서 컨테이너를 관리하기 위하여 사용합니다.
[3] Compute Engine : 최대한의 제어 및 유연성 확보를 위해 고유한 클라우드 기반 인프라를 구축
위의 두 가지 경우가 아닐 때 Compute Engine을 이용할 수 있습니다.
* 완전한 조작이 가능합니다.
* OS 수준의 변화를 만들 수 있습니다.
* 기존 코드의 변경 없이 클라우드로 옮길 수 있는 능력이 있습니다.
* 사용자의 VM 이미지를 사용할 수 있습니다.
주의 ) 시스템이 강력한 컴퓨팅 인프라를 제공하지만, 사용하려는 플랫폼 구성요소를 개발자가 선택하고 구성해야 합니다.
컴퓨팅 서비스에 관해 좀 더 자세히 알고 싶다면 공식 문서를 참고하시기 바랍니다!
2.3 데이터 스토리지 옵션 계획하고 구성하기 ( Planning and configuring data storage options )

작업을 하기 위해 필요하거나, 작업의 결과로 나오는 데이터는 굉장히 중요합니다.
그런 데이터가 생기면 생각해봐야 하는 것이 있습니다.
1) 동적 데이터와 관련된 내용으로 데이터를 저장할 때 어떤 데이터 베이스를 쓰는 것이 가장 좋을지 결정해야 합니다. ( Product choice )
2) 정적 데이터와 관련된 내용으로 데이터의 저장과 검색에는 그에 맞는 요금이 지불되어야 합니다. 그러면 데이터의 저장과 검색 패턴에 맞는 스토리지 옵션(클래스)을 고려해야 합니다. ( Choosing storage options )
먼저 데이터베이스와 스토리지의 차이에 대해서 이해할 필요가 있습니다.
Storage could be a file or object storage which is a physical disk. Database is some sort of organised data store is a logical store.
스토리지가 물리적인 저장소의 개념이라면, 데이터베이스는 데이터가 특정 방식으로 저장되는 방식, 즉 논리적인 저장소 개념이라고 생각하면 됩니다.
데이터 데이터베이스 비교

데이터를 저장하는 구조에 따라 총 4개의 카테고리 안에 6개의 데이터 스토리지/데이터베이스 옵션이 존재함을 볼 수 있습니다.
* 관계형 데이터베이스( Relational ) : 구조화된 행, 열 구조로 데이터를 저장하며 데이터는 SQL문을 통해 검색됩니다.
=> Cloud SQL / Cloud Spanner
( 관계형 데이터베이스를 사용하는 예시는 이커머스 사이트 또는 콘텐츠 관리 시스템을 예로 들 수 있습니다. 왜냐하면 이러한 서비스는 데이터 무결성이 유지되는 관계형 데이터베이스의 특성을 선호하기 때문입니다. )
* 비관계형 데이터베이스( Non-relational ) : 비관계형 데이터베이스는 여전히 데이터 간의 관계를 만들 수 있지만, 데이터간의 연결을 데이터베이스에서 제한하지 않습니다. 관계형 데이터베이스의 경우 데이터가 복잡해지고 관계가 복잡하게 형성되는 경우 데이터베이스 변경이 필요한 상황에서 수정이 매우 힘들어 지는 경우가 있습니다. 비관계형 데이터베이스에서는 이러한 제약이 없으므로 유지 보수 및 확장이 쉽습니다.
=> Cloud Datastore / Cloud Bigtable
( 매우 대규모의 트래픽을 예상한다면 Cloud Bigtable이 그런 트래픽을 처리하기에 좋은 데이터베이스이다! )
* 오브젝트 데이터베이스( Object database ) : 데이터가 대규모의 binary large objects(BLOB) 형태로 저장되는 데이터 베이스입니다.
BLOB은 일반적으로 그림, 오디오, 또는 기타 멀티미디어 오브젝트인 것이 보통입니다.
=> Cloud Storage
( 즉, 많은 이미지 또는 다른 이진 미디어(binary media) 파일을 저장하고자 한다면 Cloud Storage를 고려해볼 수 있습니다. )
* 데이터 웨어하우스 ( Warehouse ) : SQL을 사용하지만, 데이터베이스 내에서 막대한 실시간 데이터 스트리밍 트래픽에 대한 분석 및 보고가 이뤄질 수 있도록 만들어진 데이터베이스이다.
=> Bigquery
데이터 스토리지 비교

구글의 많은 스토리지는 완전 관리(fully-managed)됩니다. 이 말은 업그레이드와 같은 단순 작업은 구글이 알아서 해주니 걱정을 하지 않아도 된다는 말입니다. 그러나, 항상 데이터 백업에 대한 관심은 가지고 있어야 합니다.
스토리지 클래스 선택

스토리지 옵션은 4개의 타입(Multi-Regional, Regional, Nearline, Coldline)으로 이루어져 있습니다.
[ 표준 스토리지 - 높은 성능의 객체 저장소를 위해 사용, 짧은 기간 동안 저장되는 데이터에 적합 ]
* Multi-Regional : 자주 액세스 하는 데이터, 웹 사이트 콘텐츠, 대화형 작업의 부하, 모바일 및 게임 애플리케이션의 데이터 일부분을 저장하는데 적합합니다.
( 지리적인 중복을 가질 수 있으며 적어도 두 지점의 지리적 거리가 160킬로미터 이상 떨어져 있는 데이터센터에 데이터를 각각 저장합니다. eg. us, eu, asia )
* Regional : Region에 사용되는 경우 표준 스토리지는 데이터를 사용하는 Google Kubernetes Engine 클러스터 또는 Compute Engine 인스턴스와 동일한 위치에 데이터를 저장하는 데 적합합니다. 리소스를 공동으로 배치하면 데이터 집약적인 계산의 성능을 극대화하고 네트워크 비용을 줄일 수 있습니다.
( Multi-Regional 보다 가격이 싸며 데이터가 덜 중복됩니다. eg. us-central1, europe-west1 etc.. )
[ 백업과 보관을 위한 저장소로 사용 ]
* Nearline : 액세스 빈도가 낮은 데이터를 저장하기 위한 저가의 내구성 높은 스토리지 서비스입니다.
( 최소 저장 기간이 30일이며, 평균적으로 한 달에 한 번 정도 읽거나 수정할 계획인 데이터를 저장하는 데 적합합니다. )
* Coldine : 데이터 보관, 온라인 백업, 재해 복구를 위한 매우 저렴한 비용의 내구성 높은 스토리지 서비스입니다.
( 가용성이 약간 낮고 최소 저장 기간이 90일이며 데이터 액세스 비용과 높은 운영 비용이 들기 때문에 일 년에 한 번 정도만 액세스 하려는 데이터에 가장 적합합니다. )

Multi-Regional 스토리지 클래스가 모든 스토리지 클래스 중에서 저장하는 데 가장 큰 비용이 들어가며, 반대로 Coldline 스토리지 클래스는 모든 스토리지 클래스 중에서 저장된 데이터를 읽는 데 가장 큰 비용이 들어갑니다. ( 스토리지 클래스의 목적과 반대되는 행동에 대해 높은 비용을 부과한다고 생각하면 이해하기가 쉬울 것입니다. )
스토리지에 관해 더 자세히 알고 싶다면 공식 문서를 참고하시기 바랍니다. 데이터베이스에 관해서는 각 데이터베이스 제품별로 공식 문서가 작성되어 있으니 참고하시길 바랍니다.
2.4 네트워크 리소스 계획하고 구성하기 ( Planning and configuring network resources )

컴퓨트 리소스를 할당하고, 어떻게 데이터를 저장할지 결정했다면 서버와 데이터의 액세스를 구성하는 방법을 결정해야 합니다. 그리고 이번에는 로드 밸런싱(load balancing)에 관해 집중해보고자 합니다.
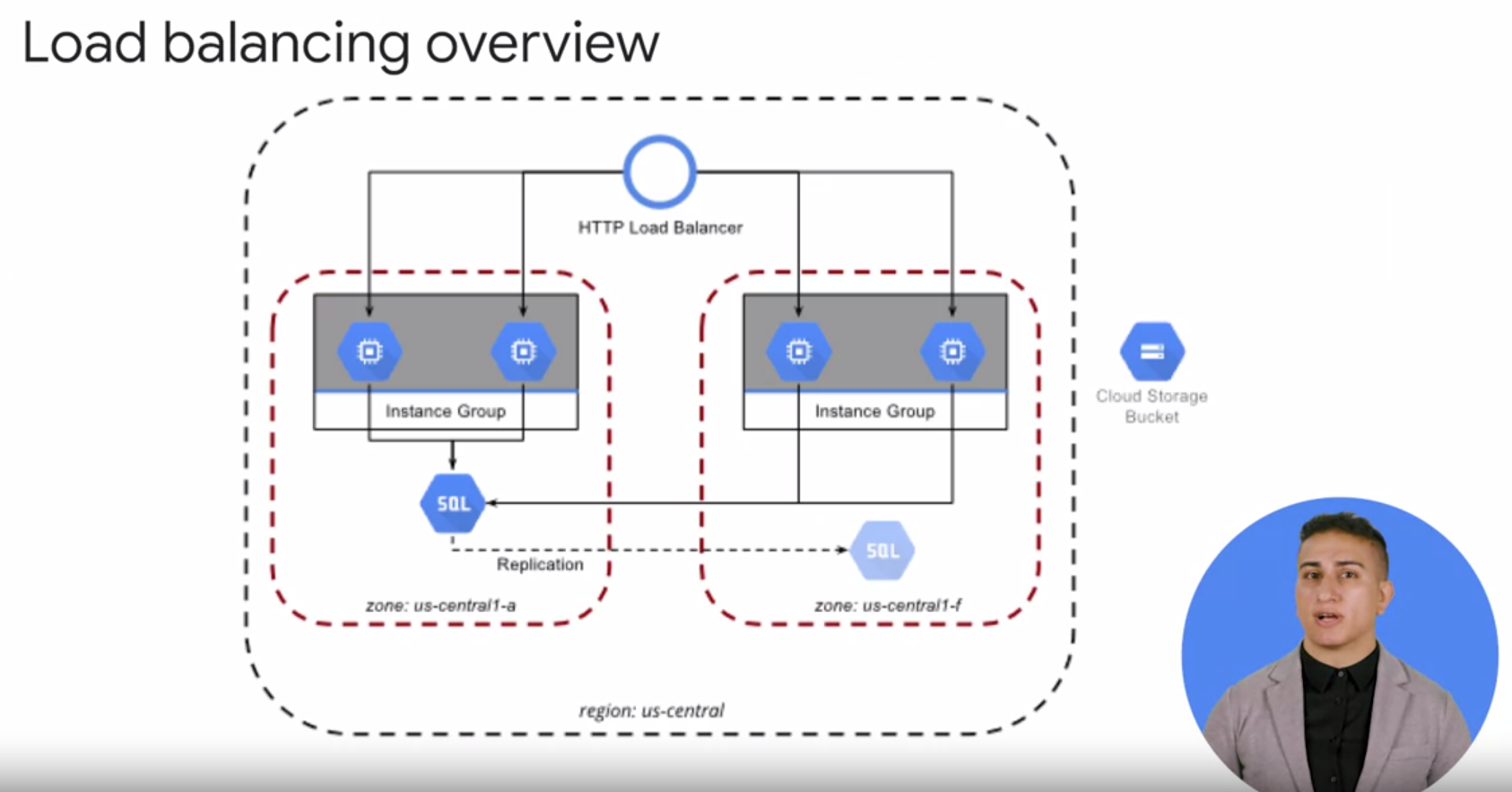
웹사이트 또는 애플리케이션이 Compute Engine에서 실행될 때는, 여러 인스턴스 간에 작업 부하(load)를 분산해야 할 경우가 발생할 수 있습니다. 이럴 경우 로드 밸런싱을 사용하여 문제를 해결할 수 있습니다.
로드 밸런싱 : 동일한 클러스터를 둘 이상 생성하여 과부하가 생기거나 하나 이상의 서버에 장애가 발생하면 나머지가 지원하거나 로드를 받아서 지속적인 서비스가 가능하게 해 줍니다. 즉 애플리케이션과 서비스가 고가용성을 가지도록 만들어줍니다.
즉, 로드 밸런서는 여러 개의 서비스 또는 서버 클러스터가 하나의 컴퓨팅 리소스로 기능하게 해 준다고 볼 수 있습니다. 그리고 로드 밸런서는 수요(트래픽)를 더 잘 만족시키기 위해 시스템 상으로부터 서버 또한 서버 클러스터를 자동으로 증설하거나 제거할 수도 있습니다. 로드 밸런서의 이런 기능을 auto-scaling이라고 합니다.

*참고: VPC 네트워크는 GCP 내에서 가상화된다는 점을 제외하면 실제 네트워크와 동일한 방식으로 생각할 수 있습니다.
로드밸런서를 사용하려면 다음과 같은 측면을 고려해야 합니다.
- 전역 로드 밸런서와 리전별 로드 밸런서
- 외부 로드 밸런서과 내부 로드 밸런서
- 트래픽 유형 ( HTTP(S), SSL, TCP, UDP 등)
[외부 로드 밸런서] : 인터넷에서 Google 네트워크로 오는 트래픽을 처리하기 위함
* Global HTTP(S) : 웹 애플리케이션을 위해 HTTP 또는 HTTPS 트래픽에 대한 로드 밸런싱이 필요한 경우 사용할 수 있습니다. (전역)
* Global SSL Proxy : HTTP(S)가 아닌 SSL(Secure Sockets Layer) 트래픽을 위한 로드 밸런싱이 필요할 때 사용할 수 있습니다. (전역)
* Global TCP Proxy : SSL을 사용하지 않는 다른 TCP 트래픽에 대한 로드 밸런싱이 필요할 경우 사용할 수 있습니다. (전역)
( Global SSL Proxy와 Global TCP Proxy는 특정한 포트 번호에서만 사용할 수 있습니다. )
* Regional : 만약 UDP 트래픽이나 다른 포트 번호(HTTP, TCP 외)의 트래픽에 대해 동일 리전상에서 트래픽을 분산시키기 위해서 사용할 수 있습니다. (지역)
주의) 외부 로드 밸런서를 사용하기 위해서는 프리미엄 티어가 필요합니다.
[내부 로드 밸런서] : 애플리케이션의 프레젠테이션 계층과 비즈니스 계층 사이의 통신과 같이 프로젝트 내의 트래픽을 처리하기 위함
* Regional internal : GCP 내부 IP 주소에 대한 트래픽을 처리하며 같은 리전내 Compute Engine VM들 사이에서 부하를 분산합니다.
내부 로드 밸런서는 기본 티어로도 사용 가능합니다.

로드 밸런서를 선택하기 위한 흐름을 보고 싶다면 흐름 차트를 참고하시기 바랍니다.
로드 밸런서에 대해 자세히 알고 싶다면 공식 문서를 참고하시기 바랍니다.
로드 밸런서에 관한 실습을 하고 싶다면 Qwiklab: 네트워크 및 HTTP 부하 분산기 설정하기를 참고하시기 바랍니다.
지금까지 클라우드 솔루션을 계획하고 구성하는 방법에 대해서 알아봤습니다. 읽으시고 이해가 안되시는 부분이 있다면 댓글로 남겨주시면 감사하겠습니다. :)
정리해보면
1. Pricing Calculator을 이용해 사용할 서비스에 대한 요금을 일, 주, 월, 년 단위로 예측해볼 수 있다.
2. 컴퓨트 리소스는 Compute Engine(제어 및 유연성을 극대화 / 사용자 관리), App Engine(구글이 완전 관리), Google Kubernetes Engine (컨테이너 애플리케이션 사용 시) 등으로 나눠볼 수 있다. + Cloud Function도 존재(Serverless)
3. 관계형 데이터베이스 ( Cloud SQL / Cloud Spanner ) , 비관계형 데이터베이스 ( Cloud Datastore / Cloud Bigtable), 오브젝트 데이터베이스 ( Cloud Storage ) , 데이터 웨어하우스 ( Bigquery )
4. 스토리지 옵션은 ( 잦은 액세스 : Multi-regional, regional ) , ( 드문 액세스 : nearline, coldline )으로 나뉜다.
5. 네트워크 트래픽 분산을 위해 로드 밸런서를 사용한다. 전역/지역, 외부/내부, 트래픽 유형에 따라 적절한 로드 밸런서를 선택해야한다.
'클라우드 > GCP' 카테고리의 다른 글
| 한 번 빌드해 Anthos로 클라우드와 온프레미스에서 구동하기 요약 (조병욱님) (3) | 2019.12.13 |
|---|---|
| [Associate Cloud Engineer Study Guide] 정리 (1) - 클라우드 서비스 타입 (0) | 2019.12.07 |
| [Coursera] Google Cloud Associate Engineer Prepare - Week 3-2( 결제 관리와 CLI) (0) | 2019.11.25 |
| [Coursera] Google Cloud Associate Engineer Prepare - Week 3-1 (프로젝트와 계정) (0) | 2019.11.21 |
| [Coursera] Google Cloud Associate Engineer Prepare - Week 2 (0) | 2019.11.21 |



